
Sentiment140 is a tool that allows you to evaluate a written text in order to determine if the writer has a positive or negative opinion about a specific topic. Facing 2015 Argentinian presidential election we are going to evaluate the public image of the most important candidates: Sergio Massa, Mauricio Macri and Daniel Scioli. For this purpose we are going to use the python library called Tweepy to collect thousands of tweets in which they are mentioned.
What is sentiment analysis?
Sentiment analysis aims to determine the attitude of a speaker or writer with respect to some topic or the overall contextual polarity of the document. The attitude may be his or her judgment or evaluation, affective state or the intended communication.
Written text can be broadly categorized into two types: facts and opinions.
- Opinions carry people’s sentiments and feelings. These kind of texts can be classified in positive or negative. For example if we get the following text: “I would like to see Macri as president” we can suppose that the speaker has a positive opinion about the candidate. In the same way, if we get the text: “I wouldn’t like to see Macri as president” we can suppose that the speaker has a negative impression about him.
- A fact can be for example: “Today Macri visited three neighborhoods“. We should ignore these kind of texts because we can’t determine if the writer has a positive or a negative opinion about the politician.
Analyzing sentiment on a regular basis will help you understand people’s feelings towards your company, brand, your product or whatever you want to analyze.
Sentiment140
There are a few free tools available which provide automatic sentiment analysis. One of the most used nowadays is Sentiment140. This is an API that uses machine learning algorithms to classify tweets. Sentiment140 was created by three Computer Science graduate students at Stanford University (Alec Go, Richa Bhayani and Lei Huang).
How to get the data?
In order to get thousands of tweets about each candidate, Tweepy is a very used python library for accessing the Twitter API.
Installation
The easiest way to install Tweepy is using PIP, if you have this tool open a command line and type:
|
1 |
$ pip install tweepy |
If not, you can use Git to clone the repository and install it manually:
|
1 2 3 |
$ git clone https://github.com/tweepy/tweepy.git $ cd tweepy $ python setup.py install |
Get Started with Tweepy:
We won’t get into much detail here about the library but below there is an example about how to get tweets from a specific topic and put them in an array:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import tweepy from tweepy import OAuthHandler CKEY = "CONSUMER KEY -- get it from dev.twitter.com" CSECRET = "CONSUMER SECRET -- get it from dev.twitter.com" ATOKEN = "ACCESS TOKEN -- get it from dev.twitter.com" ATOKENSECRET = "ACCESS TOKEN SECRET -- get it from dev.twitter.com" POLITICIAN = "Candidate's_Name" LANGUAGE = 'es' LIMIT = 2500 # Number of tweets auth = OAuthHandler(CKEY, CSECRET) auth.set_access_token(ATOKEN, ATOKENSECRET) api = tweepy.API(auth) tweets = [] for tweet in tweepy.Cursor( api.search, q=POLITICIAN, result_type='recent', include_entities=True, lang=LANGUAGE).items(LIMIT): tweets.append(tweet) print tweets |
Once having the necessary tweets, as in the example, we have 2500 tweets about a candidate in an array, we need to pass these tweets to Sentiment140 API in order to catalog them.
Requests
Requests should be sent via HTTP POST to “http://www.sentiment140.com/api/bulkClassifyJson”. The body of the message should be a JSON object. Here’s an example:
|
1 2 3 4 |
{ "data" : [{ "text": "I want to Macri as president", "id": 15486254, "query": "Macri", "language": "es" }, { "text": "I do not want to Macri as president", "id": 2364454, "query": "Macri", "language": "es"}]} |
We can ignore some fields in the request like “id”, “query” and “language” but it’s recommended to provide the field ‘query’ to prevent certain keywords from influencing sentiment.
Response
The response will be the same as the request, except for a new field “polarity” added to each object. In our example the response will be:
|
1 2 3 4 |
{ "data" : [{ "text": "I want Macri as a president", "id": 15486254, "query": "Macri", "language": "es", "polarity": 4 }, { "text": "I do not want Macri as president", "id": 2364454, "query": "Macri", "language": "es", "polarity": 0}]} |
The polarity values are:
- 0 : negative
- 2 : neutral
- 4 : positive
There are no explicit limits on the number of tweets in the bulk classification service, but there is timeout window of 60 seconds. That is, if the request takes more than 60 seconds to process the server will return a 500 error.
In the candidates’ example, we used the python library urllib2 to send the data via HTTP POST, so the complete code to evaluate a candidate is the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
#!/usr/bin/env python from tweepy import OAuthHandler import tweepy import urllib2 import json from unidecode import unidecode CKEY = "CONSUMER KEY -- get it from dev.twitter.com" CSECRET = "CONSUMER SECRET -- get it from dev.twitter.com" ATOKEN = "ACCESS TOKEN -- get it from dev.twitter.com" ATOKENSECRET = "ACCESS TOKEN SECRET -- get it from dev.twitter.com" URL_SENTIMENT140 = "http://www.sentiment140.com/api/bulkClassifyJson" POLITICIAN = "Candidate's_Name" LIMIT = 2500 LANGUAGE = 'es' # Sentiment140 API only support English or Spanish. def parse_response(json_response): negative_tweets, positive_tweets = 0, 0 for j in json_response["data"]: if int(j["polarity"]) == 0: negative_tweets += 1 elif int(j["polarity"]) == 4: positive_tweets += 1 return negative_tweets, positive_tweets def main(): auth = OAuthHandler(CKEY, CSECRET) auth.set_access_token(ATOKEN, ATOKENSECRET) api = tweepy.API(auth) tweets = [] for tweet in tweepy.Cursor( api.search, q=POLITICIAN, result_type='recent', include_entities=True, lang=LANGUAGE).items(LIMIT): aux = { "text" : unidecode(tweet.text.replace('"','')), "language": LANGUAGE, "query" : POLITICIAN, "id" : tweet.id } tweets.append(aux) result = { "data" : tweets } req = urllib2.Request(URL_SENTIMENT140) req.add_header('Content-Type', 'application/json') response = urllib2.urlopen(req, str(result)) json_response = json.loads(response.read()) negative_tweets, positive_tweets = parse_response(json_response) print "Positive Tweets: " + str(positive_tweets) print "Negative Tweets: " + str(negative_tweets) if __name__ == '__main__': main() |
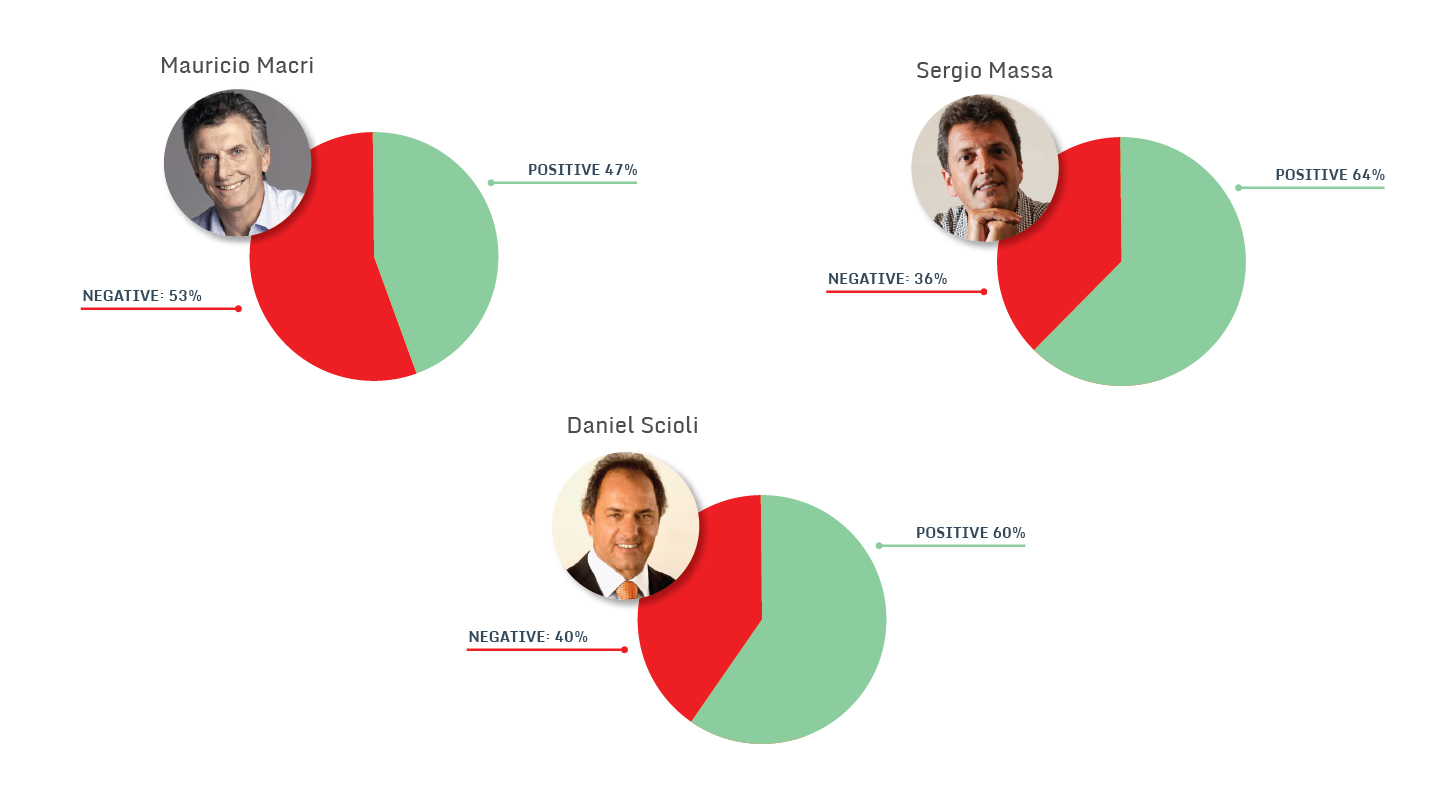
Result
In order to get a better estimation it is advised to run our program at least three times in different days and add the results to get a clearer percentage.
In our example, the result showed the following percentages:
Hi Fernando,
I was trying to do some sentiment analysis but am getting an error on line 40.
SyntaxError: Non-ASCII character ‘\xc2’ in file twitter_sentiment_analysis.py on line 40, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
can you please help me to resolve this issue